
چگونه با پایتون مدلهای هوش مصنوعی بسازیم
چگونه با پایتون مدلهای هوش مصنوعی بسازیم: راهنمای گامبهگام
چگونه با پایتون مدلهای هوش مصنوعی بسازیم: راهنمای گامبهگام
در سال 2025، پایتون به دلیل سادگی و کتابخانههای قدرتمند مانند TensorFlow و PyTorch، همچنان بهترین زبان برای ساخت مدلهای هوش مصنوعی (AI) است. این راهنمای گامبهگام، از نصب ابزارها تا اجرای مدلهای یادگیری ماشین و یادگیری عمیق، شما را همراهی میکند. اگر تازهکار هستید، پیشنهاد میکنیم ابتدا مقاله پایتون چیست؟ را بخوانید تا با این زبان آشنا شوید.

چرا پایتون برای هوش مصنوعی؟
پایتون به دلیل سینتکس ساده، کتابخانههای متنوع و جامعه فعال توسعهدهندگان، انتخاب اول برای پروژههای AI است. برای درک مفاهیم پایه هوش مصنوعی، به مقاله هوش مصنوعی چیست؟ راهنمای کامل و کاربردهای AI مراجعه کنید.
مزایای پایتون در AI
- کتابخانههای قوی: TensorFlow، PyTorch، Scikit-learn و غیره.
- سینتکس ساده: کدنویسی سریع و خوانا.
- منابع آموزشی فراوان: مانند جزوه و کتابهای رایگان پایتون.
- پشتیبانی چندپلتفرمی: اجرا در ویندوز، لینوکس و مک.
برای مقایسه با زبانهای دیگر، به پایتون یا جاوا کدام بهتر است؟ یا PHP یا Python کدام بهتر است؟ سر بزنید.
مراحل ساخت مدل هوش مصنوعی با پایتون
این راهنما مراحل کامل ساخت یک مدل AI را پوشش میدهد.
1. آمادهسازی محیط توسعه
برای شروع، پایتون و کتابخانههای مورد نیاز را نصب کنید.
- نصب پایتون: نسخه 3.10 یا بالاتر را از python.org دانلود کنید.
- نصب کتابخانهها: از pip برای نصب کتابخانههای ضروری مانند TensorFlow، PyTorch، Scikit-learn، Pandas، NumPy و Matplotlib استفاده کنید.
- محیط مجازی: برای مدیریت وابستگیها، از virtualenv استفاده کنید تا پروژههایتان سازمانیافته باقی بمانند.
برای پروژههای عملی، به ۱۰ ایده پروژه پایتون برای مبتدیان مراجعه کنید.
کد: نصب کتابخانههای مورد نیاز
توضیحات: این کد در ترمینال اجرا میشود تا کتابخانههای ضروری برای هوش مصنوعی نصب شوند.
pip install tensorflow pytorch scikit-learn pandas numpy matplotlibمحیط مجازی: برای مدیریت وابستگیها، از virtualenv استفاده کنید.
کد: راهاندازی محیط مجازی
توضیحات: این کد یک محیط مجازی برای جداسازی وابستگیهای پروژه ایجاد میکند.
python -m venv ai_env
source ai_env/bin/activate # در ویندوز: ai_env\Scripts\activateبرای پروژههای عملی، به ۱۰ ایده پروژه پایتون برای مبتدیان مراجعه کنید.
2. انتخاب کتابخانه مناسب
انتخاب کتابخانه به نوع پروژه بستگی دارد:
- Scikit-learn: برای مدلهای یادگیری ماشین ساده (رگرسیون، طبقهبندی).
- TensorFlow: برای یادگیری عمیق و پروژههای مقیاسپذیر.
- PyTorch: برای تحقیقات و مدلهای پویا.
جدول مقایسه کتابخانهها
| کتابخانه | کاربرد اصلی | سطح پیچیدگی | لینک رسمی |
|---|---|---|---|
| Scikit-learn | یادگیری ماشین پایه | مبتدی | scikit-learn.org |
| TensorFlow | یادگیری عمیق، مقیاسپذیر | متوسط تا پیشرفته | tensorflow.org |
| PyTorch | تحقیقات، مدلهای پویا | پیشرفته | pytorch.org |
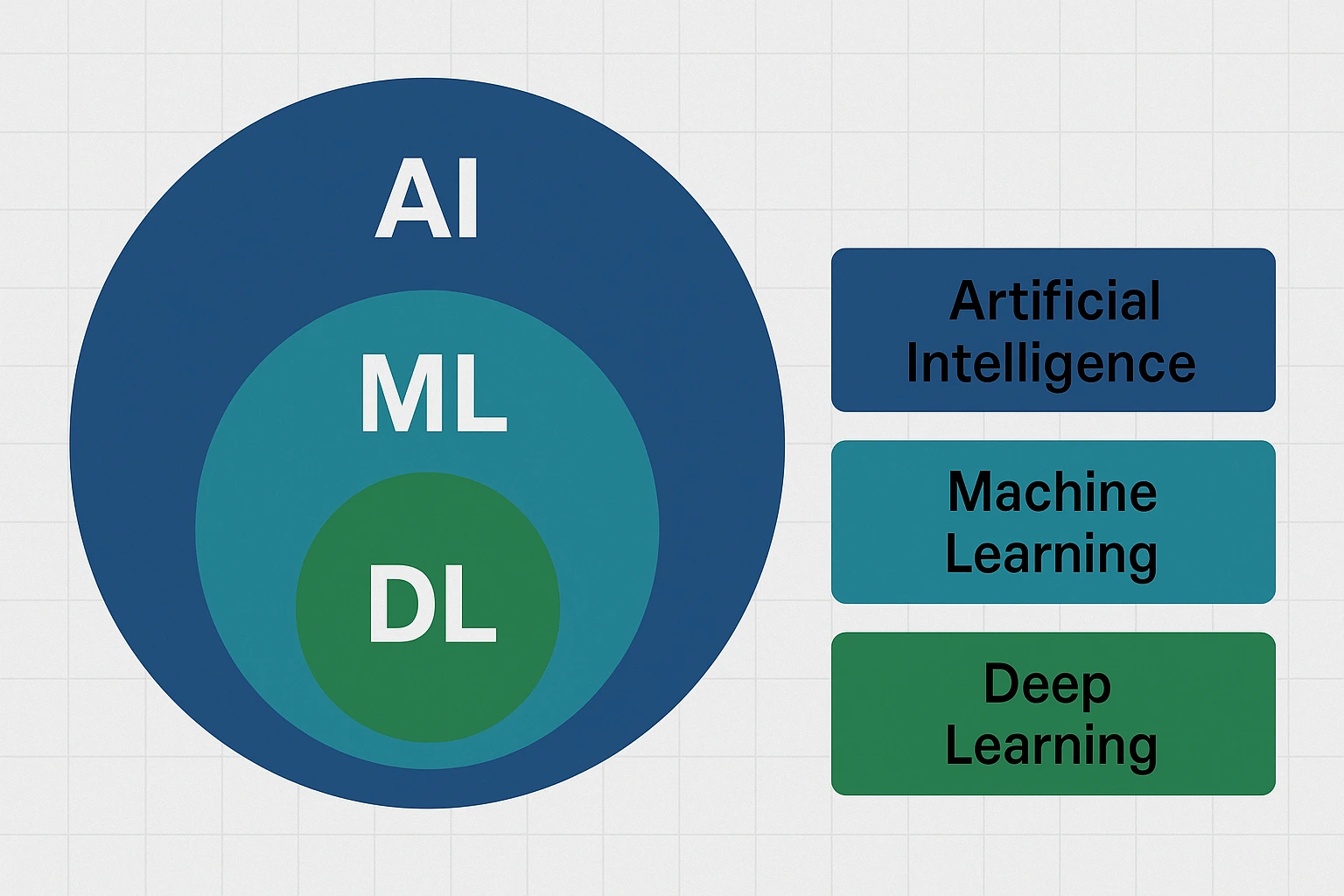
برای درک تفاوتهای فناوریهای AI، به تفاوت هوش مصنوعی، یادگیری ماشین و یادگیری عمیق مراجعه کنید.
3. جمعآوری و آمادهسازی دادهها
دادهها مهمترین بخش هر مدل AI هستند.
- جمعآوری داده: از دیتاستهای عمومی مانند Kaggle (kaggle.com) استفاده کنید.
- پاکسازی داده: دادههای ناقص یا نامناسب را با Pandas مدیریت کنید.
- نرمالسازی داده: از Scikit-learn برای استانداردسازی دادهها استفاده کنید تا مدل عملکرد بهتری داشته باشد.
برای یادگیری بیشتر تحلیل داده، به دیتا ساینس یا علم داده چیست؟ سر بزنید.
import pandas as pd
df = pd.read_csv('dataset.csv')
df = df.dropna() # حذف مقادیر گمشدهنرمالسازی داده: از Scikit-learn برای استانداردسازی دادهها استفاده کنید.
کد: نرمالسازی دادهها
توضیحات: این کد دادهها را برای آموزش مدل استاندارد میکند.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df)نرمالسازی داده: از Scikit-learn برای استانداردسازی دادهها استفاده کنید.
کد: نرمالسازی دادهها
توضیحات: این کد دادهها را برای آموزش مدل استاندارد میکند.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df)4. انتخاب مدل مناسب
مدلها بر اساس کاربرد انتخاب میشوند:
- رگرسیون خطی: برای پیشبینی مقادیر عددی (Scikit-learn).
- شبکههای عصبی: برای وظایف پیچیده مانند تشخیص تصویر (TensorFlow/PyTorch).
- درختهای تصمیم: برای طبقهبندی دادهها.
5. آموزش و ارزیابی مدل
برای آموزش مدل، دادهها را به دو بخش آموزشی و آزمایشی تقسیم کنید. از Scikit-learn برای آموزش مدلهای ساده مانند رگرسیون خطی استفاده کنید و خطای مدل را با معیارهایی مانند میانگین مربعات خطا (MSE) ارزیابی کنید. برای پروژههای پیشرفتهتر، به چطور با یادگیری پایتون وارد دنیای هوش مصنوعی شویم مراجعه کنید.
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
# بارگذاری داده
X = df_scaled[:, :-1] # ویژگیها
y = df_scaled[:, -1] # برچسبها
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# آموزش مدل
model = LinearRegression()
model.fit(X_train, y_train)
# ارزیابی
y_pred = model.predict(X_test)
print(f"خطا: {mean_squared_error(y_test, y_pred)}")برای پروژههای پیشرفتهتر، به چطور با یادگیری پایتون وارد دنیای هوش مصنوعی شویم مراجعه کنید.
6. بهینهسازی و استقرار مدل
بهینهسازی: از GridSearchCV برای تنظیمهایپرپارامترها استفاده کنید.
کد: بهینهسازی مدل با GridSearchCV
توضیحات: این کد بهترینهایپرپارامترها را برای یک مدل SVM پیدا میکند.
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
param_grid = {'C': [0.1, 1, 10], 'kernel': ['linear', 'rbf']}
grid = GridSearchCV(SVC(), param_grid, cv=5)
grid.fit(X_train, y_train)
print(f"بهترین پارامترها: {grid.best_params_}")استقرار مدل: مدل را با Flask به یک وبسرویس تبدیل کنید.
کد: استقرار مدل با Flask
توضیحات: این کد یک API ساده برای پیشبینی با مدل آموزشدیده ایجاد میکند.
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
data = request.json
prediction = model.predict([data['features']])
return jsonify({'prediction': prediction.tolist()})
if __name__ == '__main__':
app.run(debug=True)برای پروژههای وب، به بهترین ایدهها برای پروژههای جاوا مراجعه کنید.
7. نظارت و بهبود مستمر
پس از استقرار، مدل را با دادههای جدید بهروزرسانی کنید تا دقت آن حفظ شود. برای بهبود مهارتهای کدنویسی AI، به چگونه مهارتهای کدنویسی خود را با ChatGPT بهبود دهید سر بزنید.

ابزارهای کمکی برای ساخت مدلهای AI
- Jupyter Notebook: برای آزمایش و مصورسازی دادهها.
- Google Colab: محیط ابری با GPU رایگان (colab.research.google.com).
- Aider: ابزار AI برای تولید کد پایتون (aider.chat).
برای ابزارهای بیشتر، مقاله بهترین ابزارهای هوش مصنوعی برای برنامهنویسان در 2025 را مطالعه کنید.
نکات کلیدی برای موفقیت
- حریم خصوصی دادهها: از ذخیره دادههای حساس در سرورهای ابری پرهیز کنید. به هوش مصنوعی و حریم خصوصی مراجعه کنید.
- منابع آموزشی: از جزوه و کتابهای رایگان پایتون برای یادگیری عمیقتر استفاده کنید.
- رزومه حرفهای: پروژههای AI خود را در رزومهتان برجسته کنید. به رزومه با هوش مصنوعی و رزومه آلمانی (Lebenslauf) برای مهاجرت کاری سر بزنید.
نتیجهگیری
ساخت مدلهای هوش مصنوعی با پایتون در سال 2025 با ابزارهایی مانند TensorFlow، PyTorch و Scikit-learn ساده و قدرتمند است. این راهنما مراحل اصلی را پوشش داد، اما برای حرفهای شدن، پروژههای عملی را امتحان کنید. برای ایدههای بیشتر، به ۱۰ ایده پروژه پایتون برای مبتدیان مراجعه کنید. نظرات خود را در بخش کامنتها بنویسید و ما را در اینستاگرام و تلگرام دنبال کنید.
سؤالات متداول (FAQ)
- آیا برای ساخت مدل AI نیاز به دانش ریاضی پیشرفته دارم؟
خیر، اما دانش پایه آمار و جبر خطی مفید است. به دیتا ساینس یا علم داده چیست؟ مراجعه کنید. - کدام کتابخانه برای مبتدیان بهتر است؟
Scikit-learn برای شروع، TensorFlow و PyTorch برای پروژههای پیشرفته. - چگونه مدل AI خود را در رزومهام نمایش دهم؟
به اشتباهات رایج در نوشتن رزومه سر بزنید تا رزومهای حرفهای بسازید.
خیر، اما دانش پایه آمار و جبر خطی مفید است. به دیتا ساینس یا علم داده چیست؟ مراجعه کنید.
Scikit-learn برای شروع، TensorFlow و PyTorch برای پروژههای پیشرفته.
به اشتباهات رایج در نوشتن رزومه سر بزنید تا رزومهای حرفهای بسازید.
دیدگاه و پرسش
شش مقاله اخیر


دوره های برنامه نویسی برگزیده

1590000 تومان
950000 تومان
1790000 تومان

98000 تومان

100000 تومان

150000 تومان
مقالات برگزیده
مقالات مرتبط






.webp)
دوره های برنامه نویسی جدید

.webp)


برنامه نویسی وب، طراحی سایت از مقدماتی تا پیشرفته ( پروژه محور)
71
(دانشجو)3.6
( 9 نظر )
شش مقاله اخیر
مقالات مرتبط

.webp)


